





这篇文章深入探讨了Rollup的概念及其在以太坊扩容中的作用,特别是Arbitrum的实现方式。Rollup作为Layer 2扩容解决方案,通过将交易数据汇总到独立的Rollup链中,减轻了以太坊主链的负担。文章对两种主要的Rollup类型进行了对比:Optimistic Rollup(如Arbitrum)和ZK Rollup,分别介绍了它们在交易验证上的不同方法。
什么是Rollup?
以太坊的Rollup扩容是一种Layer 2(第二层)扩容解决方案,旨在提高以太坊区块链的交易吞吐量和性能。它通过将大量的交易数据转移到以太坊区块链之外的第二层网络来实现这一目标。
Rollup的核心思想是将交易数据汇总到k个称为Rollup链的智能合约中,然后将这些汇总数据提交到以太坊主链上进行验证。这样做的好处是,Rollup链可以处理大量的交易,并将结果提交到以太坊主链上进行最终的验证和确认,从而减轻了主链的负担。
目前有两种主流的rollup,一种是arbitrum所属的op rollup(乐观rollup,下面简称op),一种是zk rollup(基于零知识证明的rollup,下面简称zk).
这两者的区别主要在于以太坊验证rollup交易的方式不同。
对于 op rollup,它的原型是 – 我们默认的认为在L2上发生的交易是没问题,在默认情况下,以太坊不验证rollup的交易。当然,这里只是以太坊不验证,op方案存在链下的验证人,所以op 的交易一般都有一个供验证者验证的窗口期。
而zk rollup则与之相反,zk悲观的认为L2上的每一笔交易都是不可信的,每一笔交易都必须在以太坊原链上验证。而零知识证明在这里的作用就是,减少验证过程中的gas消耗。比如我们在L2上有一个合约执行的交易,如果L1需要验证L2的交易,我们不能把交易再放到L1上执行一次(一方面这会有很多L1,L2上的映射问题,另一方面,如果验证的时候需要再执行一遍,那我为什么不直接在L1上执行)。零知识证明做到的就是,我们在L2上做了一个复杂的操作(例如一个合约执行),我们可以为这个操作生成一个零知识证明(这里给出我的一个猜测,例如L2为一个提现操作生成了一个零知识证明 p,将p发送至L1,L1上的合约存在验证逻辑,他可以验证当且仅当L2上确实发生了对应的销毁操作,这个证明才可能被构造出来),L1上只需要验证这个证明。
在正式开始之前需要先澄清一点:
rollup并不是去执行L1上的交易,你不可能在L2上执行一个L1的合约,L2是独立于L1而存在的(在数据上来看),L2不主动拥有L1上的任何数据,他只是借用L1提供的去信任机制,L2将自己的数据,高度压缩/转换为Kz然后保存在L1上,实际上L1完全看不懂L2传过来的数据是什么意思,而他将数据保存在L1上是为了证明,在任何时候,你都可以通过L1上的这些数据还原L2的状态,从而来确保L2上数据的去信任化。
aribtrum介绍
aribtrum结构
那么我们回到arbitrum的 op rollup,我们先看一下arbitrum的整体架构图:
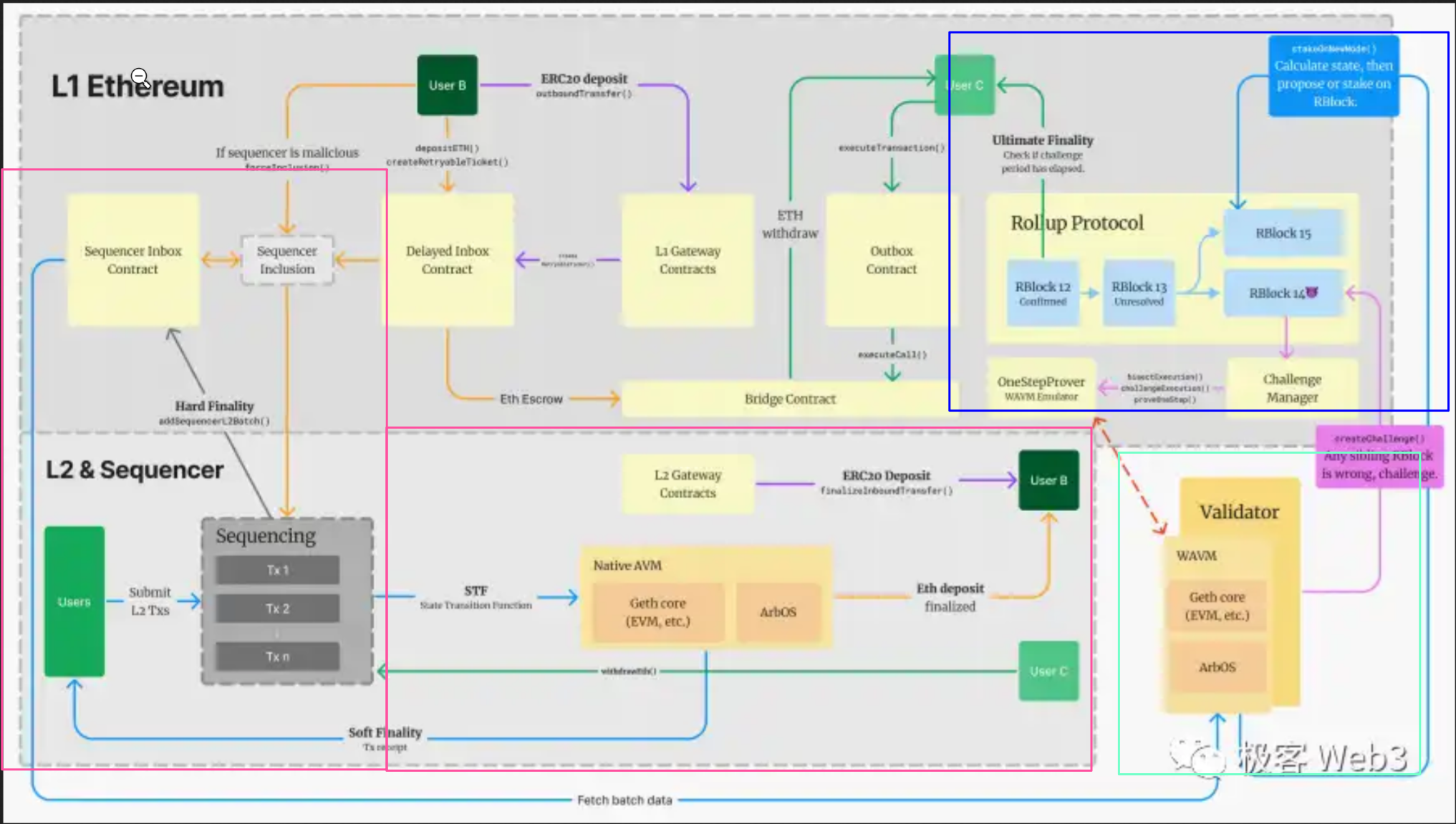
我们将aribtrum分成三个(四个)部分。第一部分是两个红色框里面的 排序器 sequencer,第二部分是绿色框中的 验证者 validator,第三部分是在L1中的蓝色框里面的rollup 合约,以及第四部分没有画框的资产桥(资产桥不影响aribtrum的主要逻辑,可以看作是aribtrum的增值服务,不过对于公链,资产桥是核心业务)
先来看一下排序器:
排序器的主要功能是将L2上的大量交易排序并打包,发送至L1里面的 sequencer inbox 合约(airbitum称之为快箱)
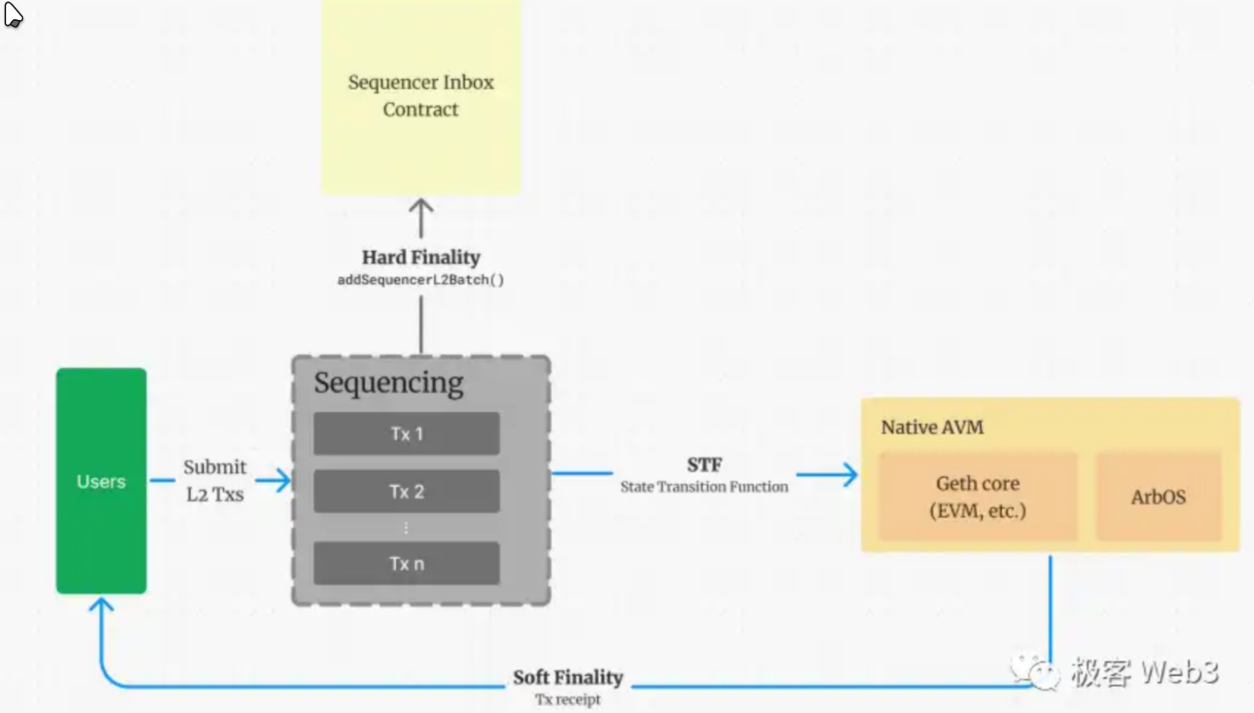
排序器主要对接用户的请求,接受用户请求,排序,执行,返回结果,排序起中一批交易一般会在0-2s内被执行(aribtrum逻辑与以太坊相似,这里的执行实际上是落快,但是排序器落快不代表最终结果,他只是因为基于以太坊,所以才有落块这个操作,实际上后面会谈到的Rblock更加贴近区块链的概念),并迅速返回结果给用户,响应速度几乎匹及web2平台。
排序器会周期性的向L2上的其他节点广播区块。另外,排序器通常会每隔几分种将这段时间内收集到的区块进行一个压缩(使用谷歌的一个压缩率还可以的算法做的压缩,这里的压缩的唯一目的是减少L1上的gas消耗)打包成一个batch保存在sequencerInbox合约中。
从以上流程中我们可以概括:Layer2 有自己的节点网络,但这些节点数量稀少,且一般没有公链惯用的共识协议,所以安全性是很差的,必须要依附于以太坊来保证,数据发布的可靠性与状态转换的有效性。
排序器实际上不参与rollup的过程,他是一个快速执行交易,打包的工具,实际上arbitrum可以不依靠排序起执行,用户可以直接把交易发送给rebitrun one 节点。
Arbitrum Rollup 协议:
定义 Rollup 链的区块 RBlock 的结构,链的延续方式,RBlock 的发布,以及挑战模式流程等⼀系列的合约。注意,这里说的 Rollup 链并不是大家理解的 Layer2 账本,而是 Arbitrum One 为了施展欺诈证明机制,而独立设置的一条抽象出来的「链状数据结构」。
⼀个 RBlock 可以包含多个 L2 区块的结果,⽽且数据也迥异,它的数据实体 RBlock 存储在 RollupCore 的⼀系列合约中。如果⼀个 RBlock 存在问题,Validator 将⾯向该 RBlock 的提交者对其进⾏挑战。
验证者 validator
Arbitrum 的验证者节点其实是 Layer2 全节点的特殊子集,目前有白名单准入。
validator是arbitrum中产生rbolck的主体,验证者节点会监听链上的dequencerInbox合约,下载排序器打包的batch来创建Rblock.同时监听以太坊上的rollup合约,验证其他节点提交的rblock,向异常rblock发起挑战。
挑战:
基础步骤可以概括为多轮互动式细分、单步证明。在细分环节,挑战双⽅先对有问题的交易数据进行多轮回合制细分,直至分解出有问题的那⼀步操作码指令,并进行验证。「多轮细分-单步证明」这种范式,被 Arbitrum 开发者认为是欺诈证明中最节省 gas 的实现方式。所有环节都在合约控制之下,没有⼀方可以作弊。
挑战期:
由于 OP Rollup 的乐观 optimistic 本质,每个 RBlock 提交上链后,合约并不主动检查,预留给验证者一段时间窗抠期去证伪。此时间窗口即为挑战期,在 Arbitrum One 主网上为 1 周。挑战期结束后,该 RBlock 才会被最终确认,块内对应的从 L2 传递到 L1 的消息(比如通过官方桥执行的提款操作)才能被放行。
挑战的原理等后面讲ArbOs的WAVM时一起讲
L2交易的生命周期
用户向排序器发送交易指令。
排序器先对待处理交易进数字签名等数据的验证,剔除无效交易,并进行排序和运算。
排序器将交易回执发送给⽤户(通常都⾮常快),但这只是排序器在 ETH 链下进行的「预处理」,处于 Soft Finality 的状态,并不可靠。但对于信任排序器的⽤户(大部分用户),可以乐观的认为交易已经完成,不会被回滚。
排序器将预处理后的交易原始数据,⾼度压缩后封装为⼀个 Batch(批次)。
**每隔⼀段时间(受到数据量、ETH 拥堵程度等因素影响),排序器会向 L1 上的 Sequencer Inbox 合约发布交易 Batch。**此时可认为,交易已拥有最终性 Hard Finality。